【amp】amp研究日記③ 〜構造化データとは〜
amp化も残りは記事内の置換の部分と構造化データに関する部分となってきました。
ampのテストを行っていると、どうやら構造化データの追加も任意ではあるが必要になってくるとのことでした。
こちら構造化が完了した際の画像

いろいろ調べたことを追記します。
構造化データとは
「HTMLで書かれた情報を検索エンジンに理解しやすいようにタグ付けしたものです。」
・リッチリザルトを表示させるためのもの
・検索エンジンにただ文字列を認識させるのではなく、文字列の意味もセットで理解させる「セマンティックWeb」という考え方が基になる
セマンティックWeb
検索エンジンに単なる文字列をとしてテキストを認識させるのではなく、
その文字の意味や背景などまで理解させようとする考え方のこと。
・W3CのTim Berners-Lee氏が提唱
・ Googleの検索エンジンのミッションは「世界中の情報を整理し、世界中の人々がアクセスできて使えるようにする」なんだとか
構造化データのメリット
メリットは主に2つ
①検索エンジンがサイトコンテンツを認識しやすくなる。
例えると「tamakipediaはWebサイト」だったものが
「tamakipediaは技術系のWebサイトで、会社は鎌倉にあり、ロゴは、、、」
のようにより細かい情報として認識させることができるようになる。
②検索結果にリッチリザルトが表示されることがある
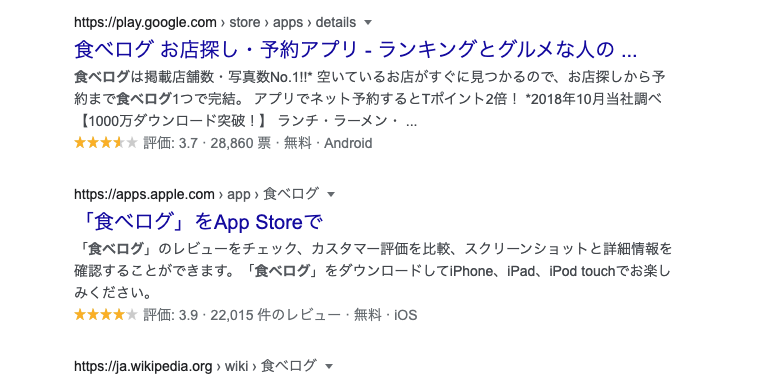 画像のような、青色リンク以外の情報も表示されるきのうのこと
画像のような、青色リンク以外の情報も表示されるきのうのこと
ボキャブラリーとシンタックス
①ボキャブラリー
何についての情報なのかを定義するような規格のこと。
・Google、Yahoo、Microsoftが策定を進めている schema.org がボキャブラリーの代表格。
・schema.org ではタイプとプロパティーを指定する記法となっている。
「名前(タイプ)にはname(プロパティー)、住所(タイプ)はaddress(プロパティー)、誕生日(タイプ)はbirth(プロパティー)」
②シンタックス
実際にマークアップする仕様のこと。
主に以下の三つがある。
・Microdata ・RDFa Lite ・ JSON-LD
・googleは JSON-LD という仕様を推奨している。
<head>
<script type="application/ld+json">
//例
{
"@context" : "http://schema.org/",
"@type":"Web service",
"name":"ECプラットフォーム(ドレス)",
"description":"この商品の特徴は、、、、",
"image":"https://......."
}
</script>
</head>
おしまい
今日は、構造化データがなんなのかについて
調べたことをまとめました。
明日は実際にwordpressサイトに構造化データを記述していこうと思います。
前回までの忘備録ももしよかったらぜひ↓↓
お疲れ様でした!!
参考:
google検索セントラル - 構造化データの仕組みについて -
https://developers.google.com/search/docs/guides/intro-structured-data?hl=ja
ほとんどこの方の記事を参考にさせていただきました。
https://digitalidentity.co.jp/blog/seo/schema-org/structured-data.html
構造化テストツール
https://search.google.com/structured-data/testing-tool/u/0/?hl=ja
schema.org の必須プロパティーに関する記事
https://www.suzukikenichi.com/blog/schema-org-articles-for-amp/
wordpress構造化データを動的に出力する
https://hirashimatakumi.com/blog/3192.html
構造化データの禁止事項
https://www.webdesignleaves.com/pr/html/amp_01.html
主なリッチリザルト
https://www.allegro-inc.com/seo/rich-snipet-schema-markup/#index_id3